分类变量是指取值属于有限、通常是非数值类别的变量。在数据分析和机器学习中,分类变量广泛存在,如性别(男性、女性、其他)、颜色(红色、蓝色、绿色等)、教育水平(高中、本科、研究生等)。由于大多数机器学习算法无法直接处理非数值数据,因此需要对分类变量进行特殊处理,将其转换为算法可接受的数值形式。
决策树是一种常用的机器学习算法,广泛应用于分类和回归任务。在处理分类变量时,决策树具有独特的优势和方法。然而,不同的实现方式对模型的性能和计算效率有着不同的影响。本文将深入探讨决策树算法在处理分类变量时的理论基础、实际应用,以及针对不同情况的处理建议。
一、理论基础:决策树算法如何处理分类变量
决策树算法在处理分类变量时,采用了一种全面而高效的方法。它不仅仅将每个类别视为独立的特征,而是通过评估所有可能的二元划分组合,寻找最优的类别划分方式。这种方法允许决策树在每个节点拆分时,充分考虑类别之间的潜在关系和相互作用,从而捕捉到数据中复杂的模式和非线性关系。
举例说明:
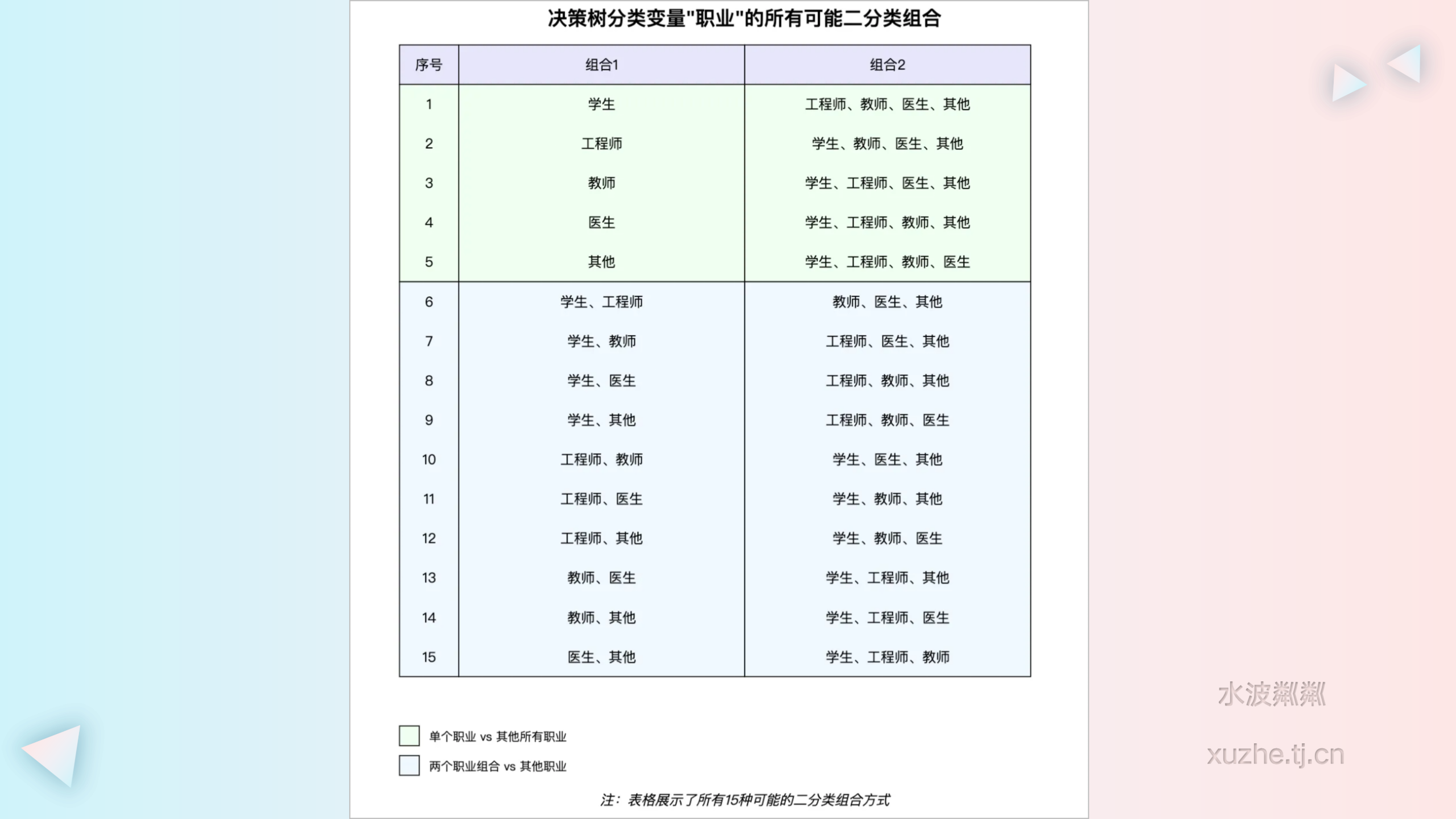
假设我们有一个用于预测客户是否会购买某产品的决策树模型,其中包含一个分类变量“职业”,其类别包括:学生、工程师、教师、医生和其他。
在这种情况下,决策树算法会考虑所有可能的职业组合来进行划分,例如:
{学生} vs {工程师, 教师, 医生, 其他}
{学生, 工程师} vs {教师, 医生, 其他}
{学生, 教师} vs {工程师, 医生, 其他}
以此类推,共有 \( (2^n - 2) / 2\)种可能的划分方式,其中 \(n\) 是类别数量。
决策树会计算每种划分方式的信息增益或基尼不纯度,选择最优的划分。这种方法能够捕捉到可能存在的复杂关系,例如“学生和工程师”这一组合可能比其他职业更倾向于购买该产品。
二、实际应用:scikit-learn中决策树的处理方式
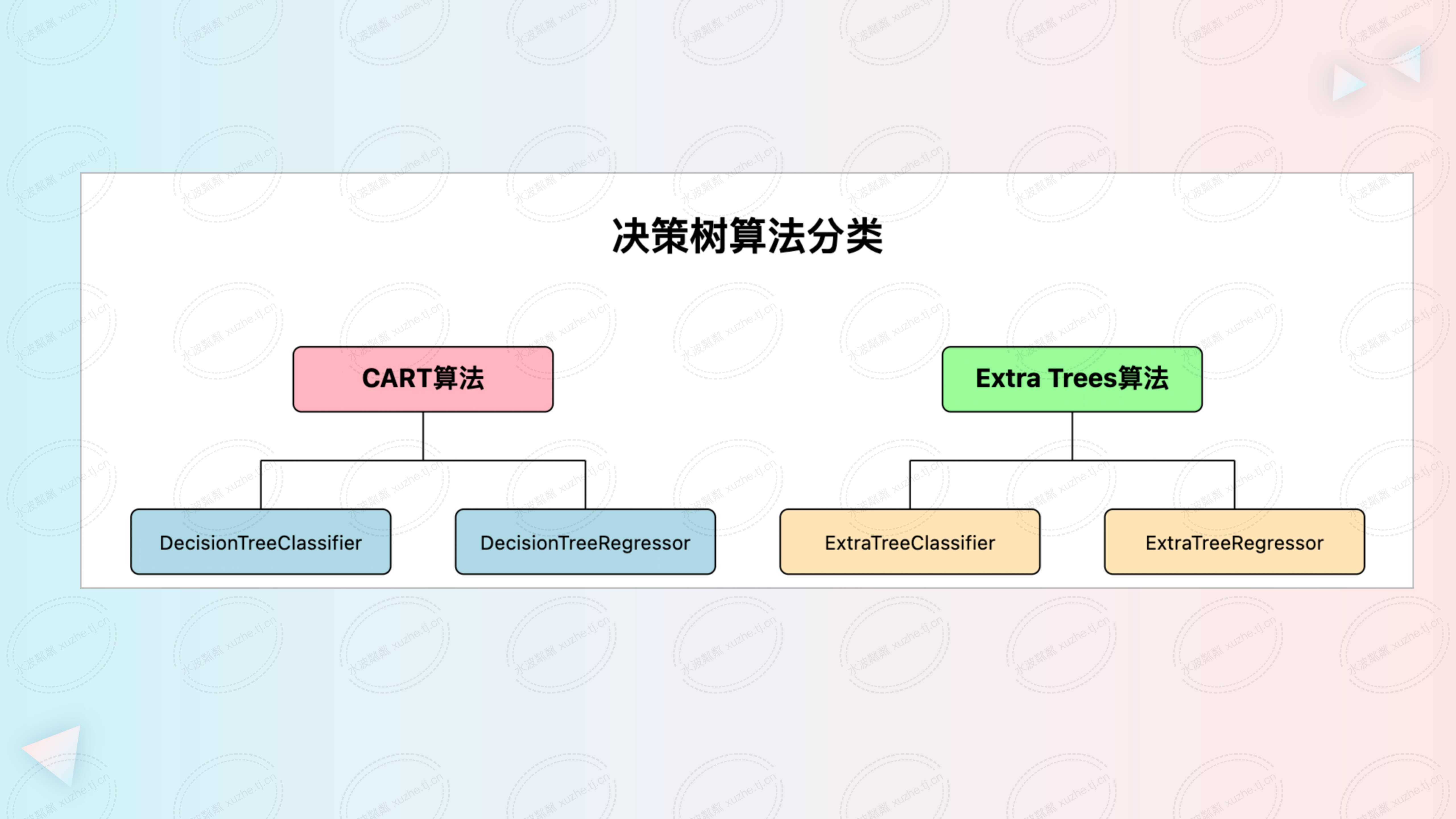
在实际应用中,Python语言因其丰富的生态系统而被广泛用于机器学习。scikit-learn 是其中一个流行的机器学习库,它提供了多种决策树算法的实现,包括:
- DecisionTreeClassifier:用于分类任务的决策树,基于 CART(Classification and Regression Trees)算法。
- DecisionTreeRegressor:用于回归任务的决策树,同样基于 CART 算法。
- ExtraTreeClassifier:极端随机树分类器,基于 Extra Trees 算法。
- ExtraTreeRegressor:极端随机树回归器,基于 Extra Trees 算法。
CART算法:
- CART 算法用于构建二叉决策树,可用于分类和回归任务。
- 在每个节点,算法通过遍历所有特征和可能的切分点,选择能最大化信息增益(分类)或最小化均方误差(回归)的分割。
- CART 决策树只能产生二元分割,即每次只能将数据集划分为两个子集。
Extra Trees算法:
- Extra Trees 是随机森林的变体,通过构建多棵随机化的决策树来降低模型的方差。
- 与随机森林不同,Extra Trees 在每个节点随机选择特征和切分点,而不是选择最优的。
- 这种极端的随机性有助于减少过拟合,提高模型的泛化能力。
然而,scikit-learn 中的决策树实现(如 CART 和 Extra Trees)在处理分类变量时,通常要求将其转换为数值形式。具体来说,需要对分类变量进行编码,例如独热编码(One-Hot Encoding)或整数编码。这是因为 scikit-learn 的实现并不直接支持原始的分类变量处理,即不支持对类别集合进行二元划分的方式。
独热编码示例:
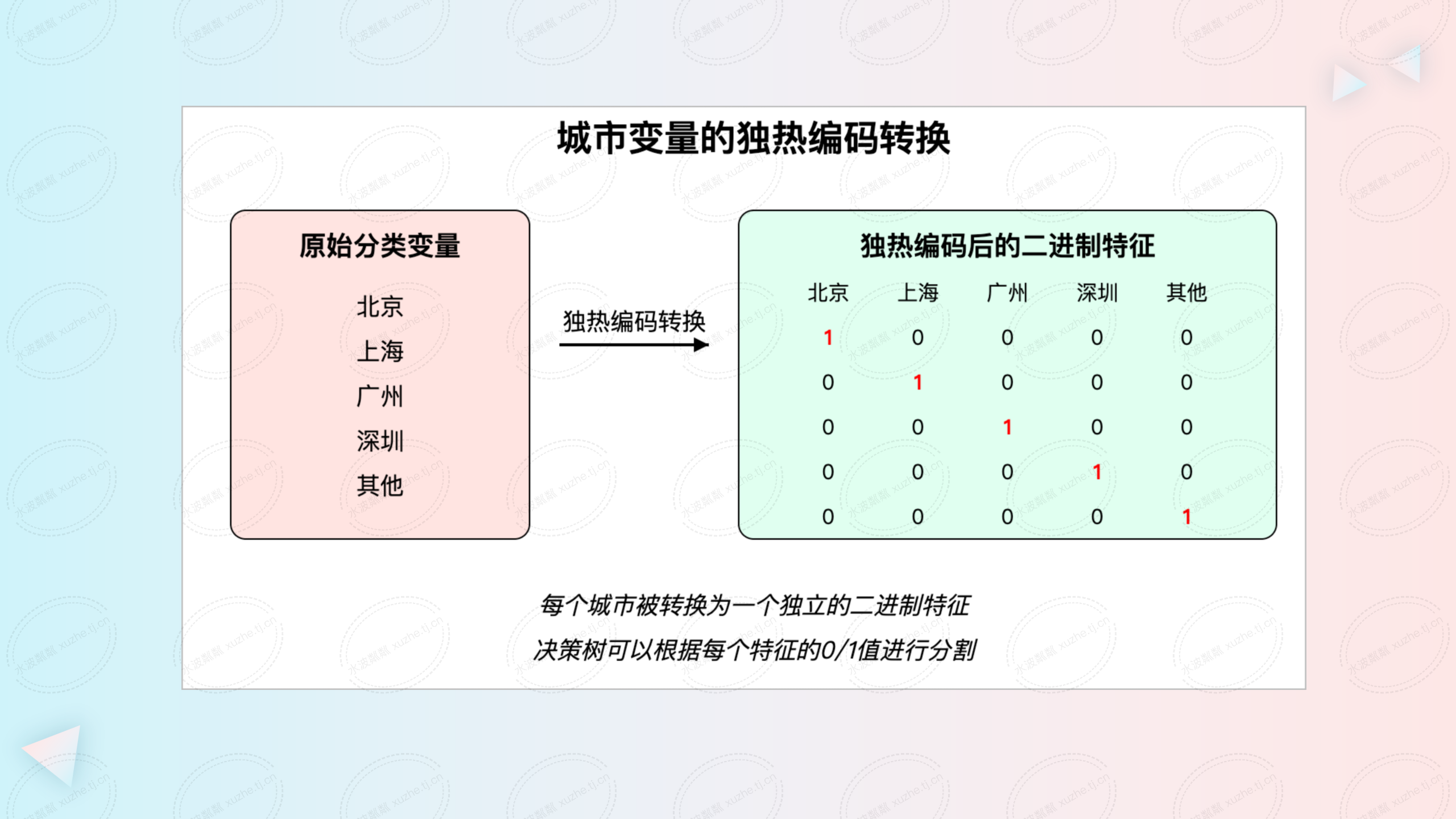
以一个包含城市信息的分类变量为例,类别包括:北京、上海、广州、深圳、其他。使用独热编码后,该变量将被转换为以下二进制特征:
• 北京:[1, 0, 0, 0, 0]
• 上海:[0, 1, 0, 0, 0]
• 广州: [0, 0, 1, 0, 0]
• 深圳: [0, 0, 0, 1, 0]
• 其他: [0, 0, 0, 0, 1]
这种编码方式将每个类别视为独立的二进制特征,决策树可以根据这些特征进行分割。例如,决策树可能会根据“是否为北京”这一特征来分割数据,而不会考虑类别之间的组合关系。
三、影响分析:不同处理方式对模型的影响
将分类变量转换为独热编码与直接处理原始分类变量,对模型的性能和计算复杂度有着显著的影响。
- 独热编码(One-Hot Encoding)
优点:
兼容性强:适用于不支持直接处理分类变量的算法,实现简单。
缺点:
- 忽略类别关系:将类别视为相互独立,无法捕捉类别之间的内在联系和交互。
- 维度增加:对于高基数(类别数量多)的变量,特征空间维度急剧增加,可能导致模型训练变慢,过拟合风险增加。
- 计算复杂度增加:高维度数据会增加模型的计算和存储成本,尤其在大数据集的情况下。
- 直接处理原始分类变量
优点:
- 保留类别关系:能够捕捉类别之间的复杂关系,提高模型的准确性和泛化能力。
- 模型更简洁:可能生成更浅、更简单的树,降低过拟合的风险。
缺点:
• 计算复杂度高:对于类别数量为 \(n\) 的变量,需要评估 \((2^n - 2) / 2\) 种可能的划分,计算量呈指数级增长。
• 实现受限:需要算法支持直接处理分类变量,部分库(如 scikit-learn)可能不支持。
计算复杂度示例:
当类别数量 \(n\) 从 1 增加到 10 时,需要评估的划分数量为:
• \(n = 1\):0 种
• \(n = 2\):1 种
• \(n = 3\):3 种
• \(n = 4\):7 种
• \(n = 5\):15 种
• \(n = 6\):31 种
• \(n = 7\):63 种
• \(n = 8\):127 种
• \(n = 9\):255 种
• \(n = 10\):511 种
可以看出,当 \(n > 5\) 时,划分可能性急剧增加,计算成本大幅上升。因此,对于高基数的分类变量,直接处理在计算上并不现实。
四、处理建议
根据上述分析,针对不同情况,提出以下处理建议:
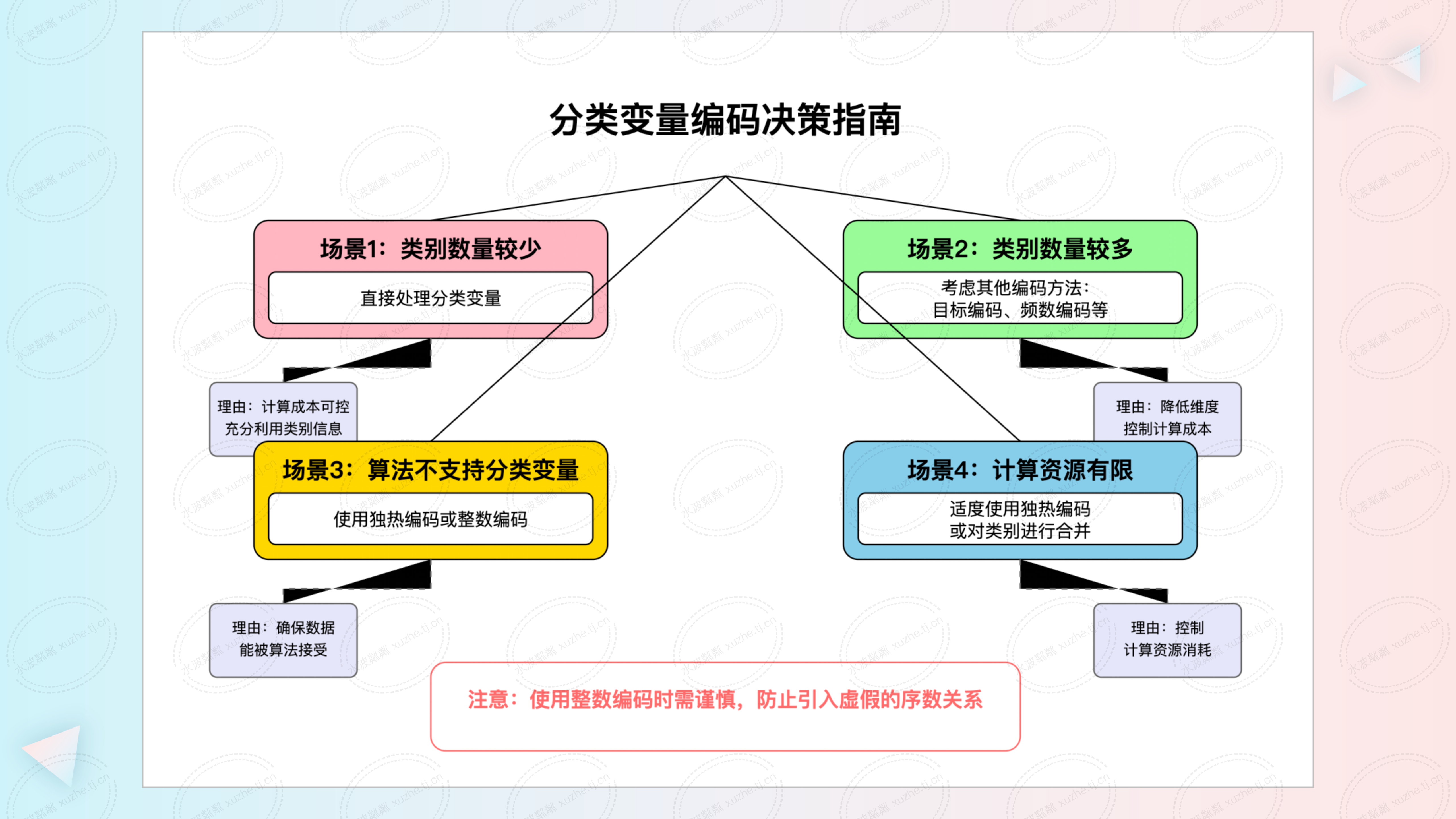
- 类别数量较少的分类变量
- 建议方法:直接处理原始分类变量。
- 理由:计算成本可控,能够充分利用类别间的关系,提高模型性能。
- 实施方式:如果使用支持直接处理分类变量的算法或库(如 XGBoost、LightGBM 等),可直接输入分类变量。
- 高基数的分类变量
- 建议方法:使用目标编码、频数编码或对类别进行合并。
- 理由:降低特征维度,控制计算成本,避免独热编码导致的维度爆炸。
- 实施方式:
- 目标编码(Target Encoding):用目标变量的平均值或概率来替代类别。
- 频数编码(Frequency Encoding):用类别出现的频率或计数来替代类别。
- 类别合并:根据业务知识或统计特性,将频次较低的类别合并为“其他”类别。
- 使用不支持分类变量的算法或库
- 建议方法:使用独热编码或整数编码(慎用)。
- 理由:确保数据能被算法接受,尽管可能有上述缺点,但在无法直接处理的情况下是必要的折中。
- 注意事项:
- 独热编码:适用于类别数量较少的情况,避免高维度问题。
- 整数编码:可能引入类别之间的序数关系,需谨慎使用。
- 计算资源有限的场景
- 建议方法:合并类别、降维或采样,控制特征维度和数据规模。
- 理由:降低计算复杂度,确保模型在有限资源下正常训练。
- 实施方式:
- 特征选择:选择重要的分类变量,剔除影响较小的变量。
- 类别合并:将低频类别合并,减少类别数量。
- 降维技术:使用主成分分析(PCA)等方法降低特征维度。
五、总结
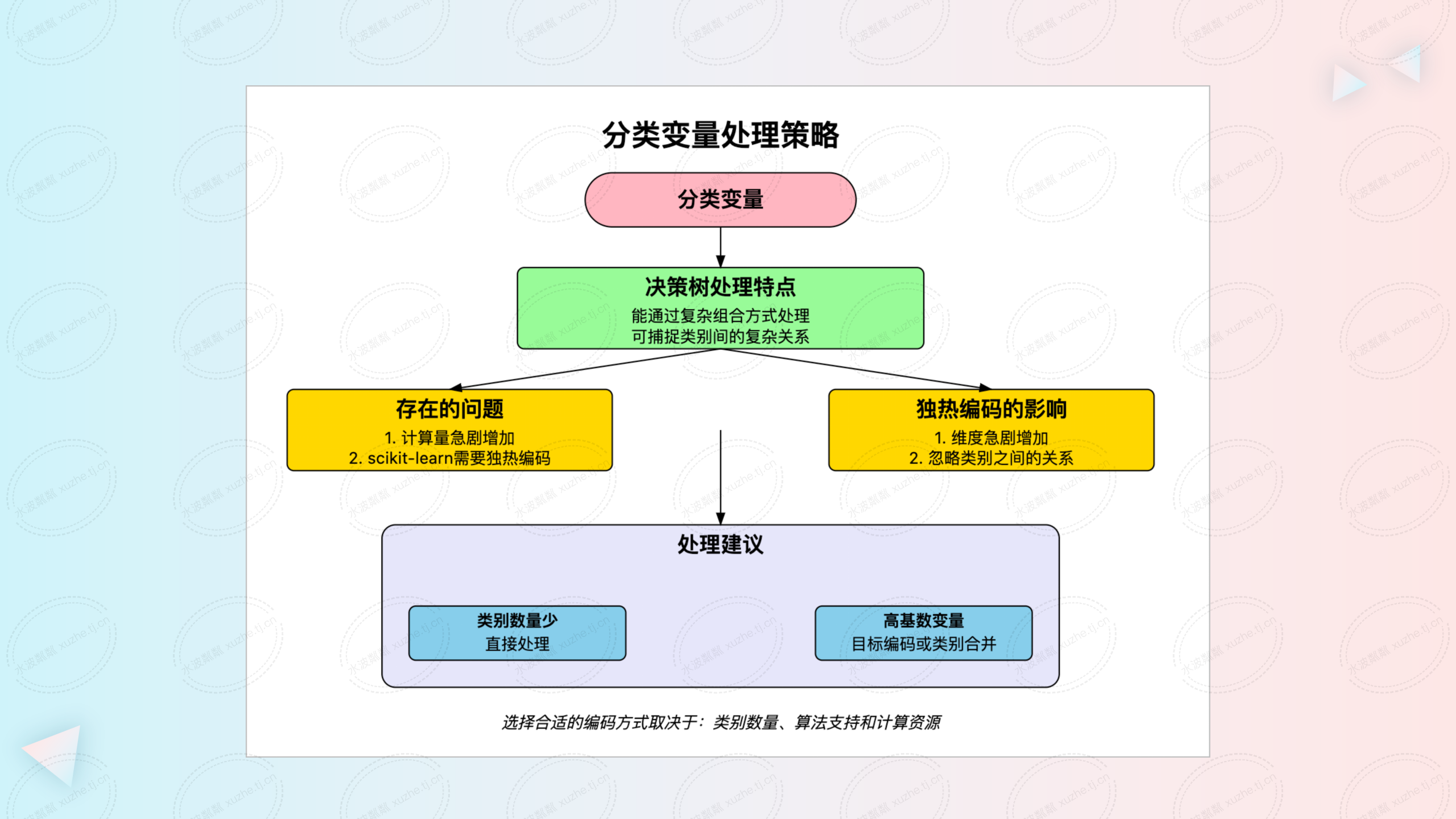
分类变量在机器学习中普遍存在,如何有效地处理这些变量对模型的性能至关重要。决策树算法在理论上具有直接处理分类变量的能力,能够通过评估所有可能的类别划分,捕捉类别之间的复杂关系。然而,在实际应用中,受限于算法实现和计算资源,直接处理高基数的分类变量并不总是可行。
对于类别数量较少的分类变量,直接处理能够充分利用数据特性,提升模型性能。对于高基数的分类变量,建议采用目标编码、频数编码或类别合并等方法,以控制特征维度和计算成本。
在选择处理方法时,需要综合考虑类别数量、算法支持、计算资源以及模型的需求。合理地处理分类变量,能够在保证模型性能的同时,提高计算效率,降低过拟合的风险。
关键要点:
- 理解算法特性:了解所使用的决策树算法是否支持直接处理分类变量。
- 评估类别数量:根据类别数量选择合适的编码方式,避免维度爆炸或计算复杂度过高。
- 利用业务知识:在进行类别合并或目标编码时,结合业务理解,确保模型的解释性和可靠性。
- 平衡性能和效率:在模型性能和计算效率之间找到平衡点,根据具体需求做出取舍。