分类变量是指取值属于有限、通常是非数值类别的变量。在数据分析和机器学习中,分类变量广泛存在,如性别(男性、女性、其他)、颜色(红色、蓝色、绿色等)、教育水平(高中、本科、研究生等)。由于大多数机器学习算法无法直接处理非数值数据,因此需要对分类变量进行特殊处理,将其转换为算法可接受的数值形式。
继续阅读标签归档:machine learning
scikit-learn的CART树——寻找分裂点的两种模式|使用技巧
CART树
CART(Classification and Regression Trees)是一种用于分类和回归任务的决策树算法。它通过选择最优特征和分裂点来构建树结构,能够有效地对数据进行分类或预测。
两种模式
CART树在寻找最佳分裂点时主要有两种模式:完全遍历模式和部分遍历模式。
继续阅读scikit-learn中的树算法 不能直接使用分类变量
scikit-learn中的算法都不直接支持分类变量
不只是scikit-learn中的树算法不能直接使用分类变量,scikit-learn中的算法都不直接支持分类变量。在使用这些算法之前,需要将分类变量转换为独热编码(one-hot)或整数类型。
继续阅读CART决策树算法:如何处理数值型与分类型特征
CART算法
决策树是一种非参数的监督学习方法,它不对数据集的分布形式做任何具体假设,但会根据数据中的特征类型和标签值动态地生成模型结构可以用于分类和回归问题。决策树的核心思想是递归地将特征空间划分为若干个单元,使得每个单元内的样本尽可能同质(即属于同一类别或具有相似的目标值)。
继续阅读特征是什么
AdaBoost | A decision-theoretic generalization of on-line learning and an application to boosting
英文题目:A decision-theoretic generalization of on-line learning and an application to boosting
中文题目:在线学习的决策理论推广及其在Boosting中的应用
作者:Yoav Freund, Robert E. Schapire
发表期刊 或 会议:Journal of Computer and System Sciences
发表日期:September 20, 1995
AdaBoost可将弱学习算法的预测精度提升到任意高的水平!这项研究不仅为在线资源分配问题提供了一个更通用的框架,还为机器学习领域带来了新的思路。AdaBoost无需事先了解弱学习算法的性能,就能自适应地调整参数,最大程度地利用弱学习算法生成的假设,从而获得惊人的预测精度。
继续阅读Maximizing diversity by transformed ensemble learning | 论文笔记
Applied Soft Computing Journal, 2019
提升集成学习:在多样性和准确性之间找到平衡
集成学习,就像一个团队合作,将多个“学习者”的预测结果结合起来,以期获得比单个学习者更准确的结果。然而,集成学习中一直存在一个挑战:如何平衡学习者之间的多样性和个体准确性?通常,多样性越高,个体准确性就越低,反之亦然。为了解决这一问题,西安电子科技大学的研究人员提出了一种新的加权集成学习方法,通过将多个学习器的组合转化为线性变换,并通过最大化多样性和个体准确性来获得最佳权重,从而在两者之间取得平衡。这项研究发表在《应用软计算杂志》上,为集成学习领域带来了新的思路。
继续阅读Reinforced quasi-random forest | 论文笔记
最小描述长度原理 | 机器学习的基础
[latexpage]
最小描述长度:一个美丽的想法,它将统计学、信息论和哲学的概念结合在一起,为机器学习奠定了基础。
最小描述长度(MDL)的概念
最小描述长度(Minimum Description Length, MDL)原理是一种基于信息论的方法,用于解决模型选择和数据压缩问题。它是由Jorma Rissanen在1978年开始的⼀系列论⽂中提出的。
标准化与规范化之间的选择 | 数据预处理的关键
标准化(Standardization)与规范化(Normalization), 有何不同?
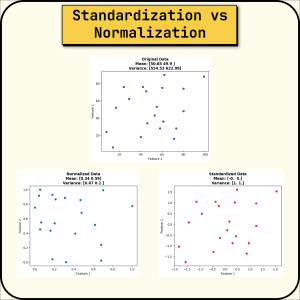
规范化(Normalization)
也称“归一化”,它将值重新缩放到 [0,1] 范围内。 它也被称为最小-最大缩放。
如果您希望不同的数据集处于相同的正比例上,这将非常有用。 它还为值创建了一个边界。